¶ Introduction
Le module Scan de Data4Citizen permet d'explorer automatiquement des sources de données (dossiers de fichiers ou bases de données géographiques) pour en extraire les ressources (documents, tables...) et alimenter le catalogue avec des jeux de données (ou des fices de métadonnées).
¶ Objectif
- Identifier des fichiers ou des tables de données existants
- Créer ou mettre à jour des jeux de données dans Data4Citizen
- Planifier des analyses régulières pour surveiller les évolutions
¶ 📍 Accéder au Module Scan
- Connectez-vous à l’interface d’administration de Data4Citizen
- Rendez-vous dans le menu Administration > Data4Citizen - atteint lorsque vous vous connectez en tant qu'administrateur de la plateforme ou administrateur d'une organsiation
- Cliquez sur le bouton
Scande la partieOpérationnel- disponible uniquement en tant qu'administrateur de la plateforme
¶ 🗃️ Gérer les cans
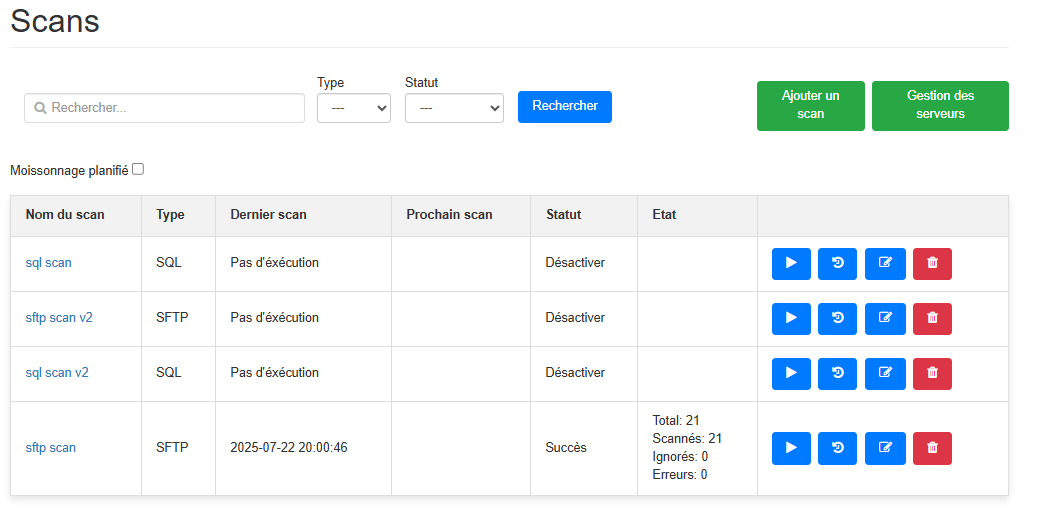
¶ Liste des Scans
La page principale affiche la liste des scans existants, avec :
- Le
nom du scan - Le
Typede source (Base SQL, SFTP, Dossier) - La date du
Dernier scan - La date du
Prochain scan- lorsque la planification est programmée - L’
Etatavec le détail (Succès / Erreur / En attente) - Des actions disponibles pour chaque scan :
- ▶️ Relancer le scan (pour détecter de nouvelles ressources)
- 🔁 Voir l'historique des exécutions du scan
- ✏️ Éditer le scan
- ❌ Supprimer le scan
¶ 🆕 Ajouter un Scan

¶ Étapes générales
Les étapes générales pour la création et la configuration d'un Scan :
|--------|-------------|
|  | 1. Accéder à l'interface des Scans (la
| 1. Accéder à l'interface des Scans (la Liste des Scan)
2. Cliquer sur « Ajouter un scan »
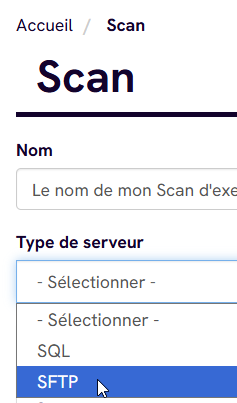
3. Nommer votre scan pour l'identifier plus facilement
4. Type de serveur
5. Sous Configuration, choisir le Serveur (le serveur doit déjà etre configuré)
- (optionnel) Planification
- Activez la planification :
- Heure d’exécution (sur la date de lancement)
- Période (quotidienne, hebdomadaire…) - Tous les
Xheures/jours/semaines/mois - Intervalle - remplace le
X
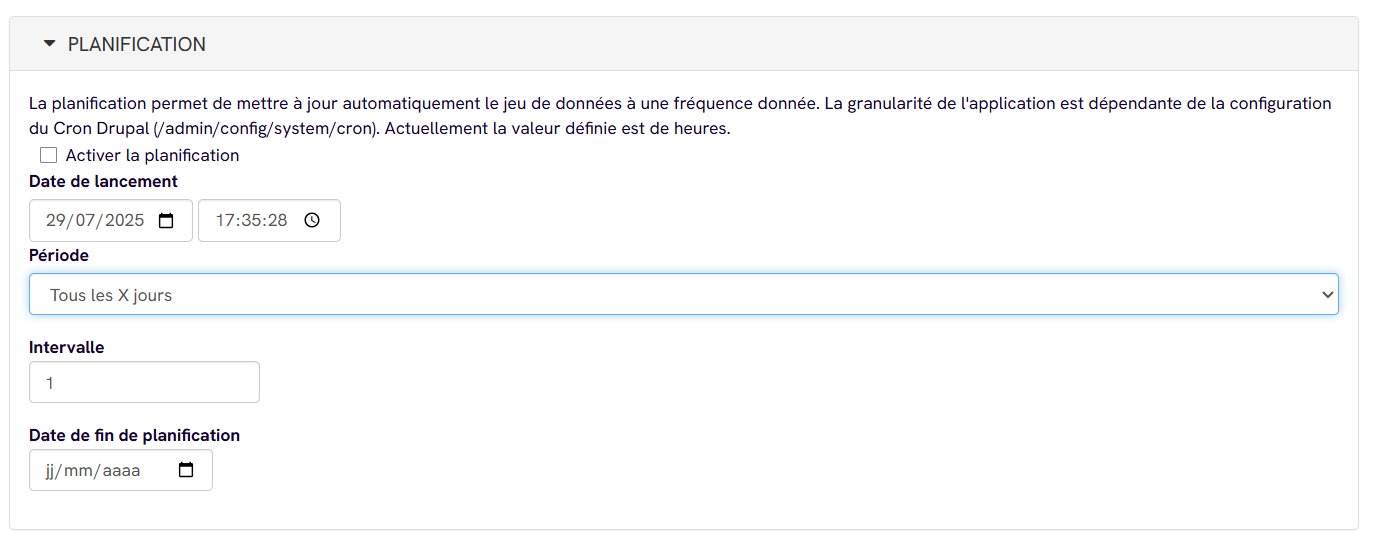
Attention, la planification se gère par le cron Drupal qui peut être configuré à "Toutes les heures" au minimum. Mais peut être configuré par une autre régularité :
/admin/config/system/cron
- Cliquez sur Soumetre pour enregistrer le scan
¶ Détail selon type de Source
¶ PostgreSQL / PostGIS
- Sélection du serveur
- Liste des bases et tables détectées
- Sélection manuelle des tables à scanner (principalement vecteurs)
- Pour chaque table sélectionnée :
- Nom du jeu de données
- Type de géométrie (point, polygone, etc.)
- Projection
¶ FTP / SFTP
- Connexion avec identifiants et chemin distant
- Affichage des fichiers détectés
- Deux options :
- Tous les fichiers
- Extensions ciblées
- Sélection possible de plusieurs fichiers (cas des rasters en dalles)
¶ Dossier local
- Chemin absolu sur le serveur
- Fonctionnement identique à FTP/SFTP
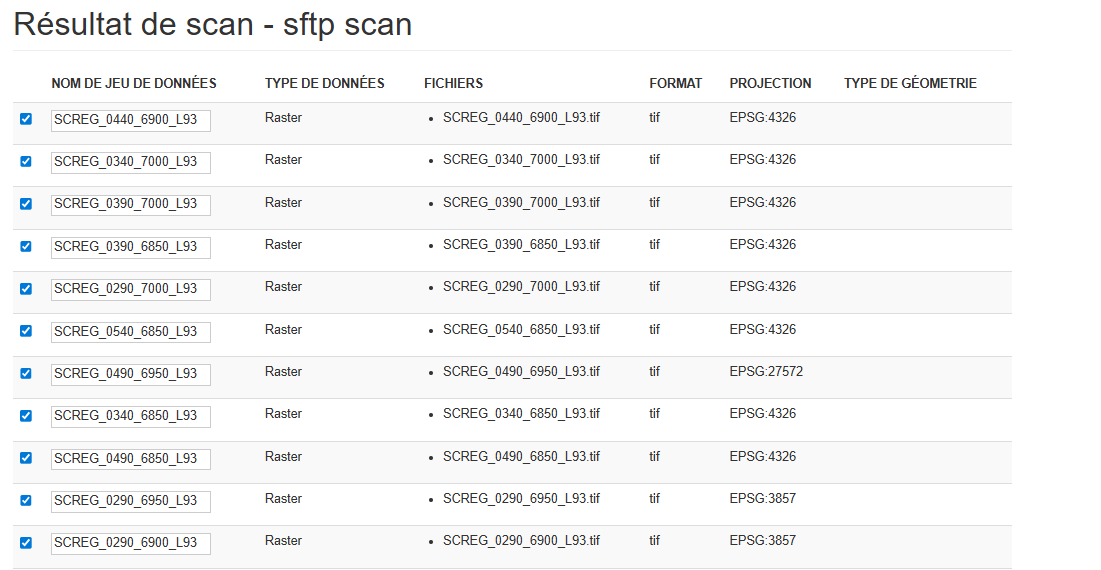
¶ 📊 Résultat du Scan
Après l’exécution d’un scan, une interface de synthèse s’ouvre avec :
| Colonne | Description |
|---|---|
| ✅ | Case à cocher (pour créer le jeu de données) |
| 🗂️ Nom du jeu de données | Déduit automatiquement ou à saisir |
| 📁 Fichiers | Liste des fichiers concernés |
| 📦 Format | Ex: GeoTiff, Shapefile, JPEG2000… |
| 🌍 Projection | Projection native du fichier |
| 🧬 Type de géométrie | Pour les vecteurs uniquement |
Vous pouvez décocher des jeux de données à ne pas créer.
¶ 🔁 Relancer un Scan
¶ Pourquoi relancer ?
Pour détecter :
- De nouveaux fichiers
- Des modifications de structure dans une base de données
¶ Fonctionnalité : Drift / Delta
Le module identifie automatiquement les nouvelles ressources non présentes lors du précédent scan, grâce à :
- Une liste interne des fichiers déjà analysés
- Le schéma SQL (DDL) déjà scanné
¶ Interface de relance
- Tableau récapitulatif avec différences détectées
- Sélection des nouvelles ressources à intégrer
- Possibilité d’envoi d’un mail de synthèse avec les changements
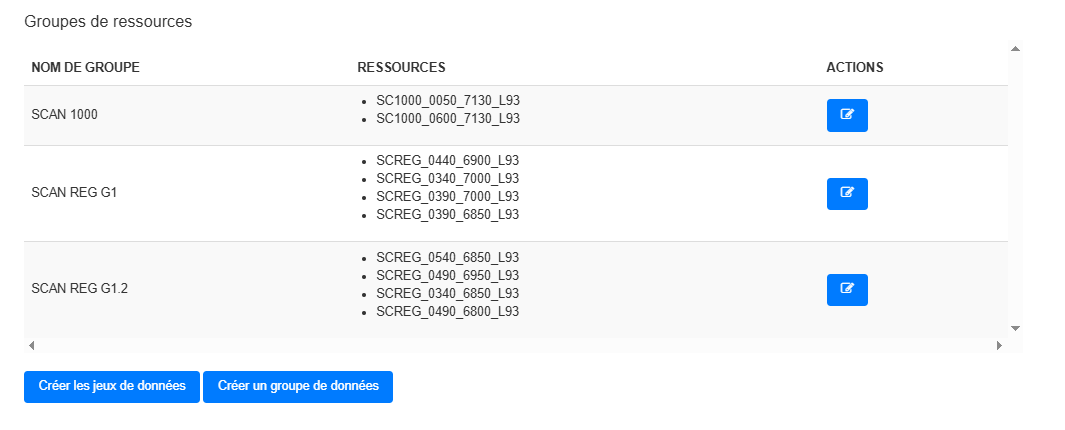
¶ 📦 Cas Particulier : Rasters et Dalles
Pour les documents raster répartis en plusieurs fichiers (dalles) :
- Le module permet de grouper plusieurs fichiers comme une seule ressource
- Résultat : un jeu de données unique avec plusieurs ressources raster
Affichage des groupes de ressources identifiés ou crées :
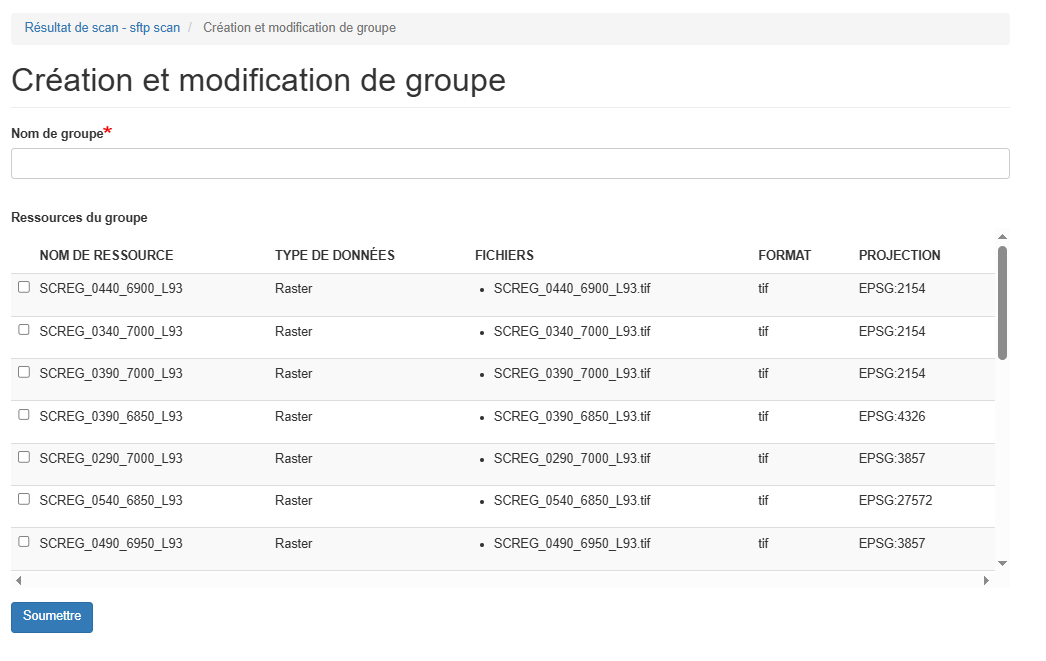
Création d'un groupe manuellement :
¶ 🖥️ Gestion des Serveurs
¶ Ajouter un Serveur Source
Depuis le menu Serveurs :
- Cliquez sur Ajouter un serveur
- Sélectionnez le type :
- PostgreSQL / PostGIS
- SFTP
- Dossier local
- Saisissez les paramètres :
- Adresse
- Chemin d’accès
- Identifiants si besoin
¶ 📬 Notifications
En option, vous pouvez :
- Activer une notification mail après chaque scan
- Recevoir un résumé des modifications détectées lors des relances (manuelles ou automatiques)
¶ 🔒 Historique et Traçabilité
Chaque jeu de données créé via un scan est tagué avec l’ID du scan d’origine, pour :
- Assurer la traçabilité
- Retrouver la source exacte des métadonnées
- Rejouer le même scan ultérieurement
¶ ✅ Bonnes Pratiques
- Créez des scans séparés pour chaque type de source (SQL vs documents)
- Utilisez la planification pour automatiser la veille
- Vérifiez les noms générés de jeux de données et ajustez-les manuellement si besoin
- Exploitez les relances régulières pour gérer les évolutions de vos sources